



أثارت تقنيات وأدوات الذكاء الاصطناعي التوليدي حقبة جديدة في صناعة التكنولوجيا؛ إذ يقول الخبراء إنها تعتبر الثورة القادمة، ويشبهها بعضهم بالثورة التي أحدثها ظهور الإنترنت نفسه. لذلك تتسابق كبرى شركات التكنولوجيا والشركات الناشئة لتقديم تقنيات ومنتجات تناسب المرحلة الجديدة من أجل الاستحواذ على حصة في سوق الذكاء الاصطناعي السريع النمو.
إذ قدمت كل من مايكروسوفت وجوجل بالفعل إصداراتهم من روبوتات الدردشة التي طُورت باستخدام نماذج اللغة الكبيرة (LLMs)، والتي يعملون على إدماج إمكانياتها في منتجاتهم الآن.
وقد وصل الأمر إلى الحكومات؛ إذ عينت حكومة رومانيا روبوت دردشة تفاعلي يُسمى (ION) كأول مستشار يعمل بالذكاء الاصطناعي لممارسة مهام حكومية، كما يستخدم العلماء برامج الذكاء الاصطناعي للوصول إلى اللغة التي يتخاطب بها الحيوانات وكيف يمكننا التواصل معها.
وقد أدت هذه السرعة في تبني تقنيات الذكاء الاصطناعي وطرح منتجات جديدة للمستخدمين إلى إثارة قلق خبراء الذكاء الاصطناعي الذين يحذرون من البيانات الموجودة عبر الويب والمستخدمة في تدريب هذه الأدوات.
كيف تمثل البيانات الموجودة عبر الويب خطرًا على الذكاء الاصطناعي؟
موضوعات ذات صلة بما تقرأ الآن:
يحذر خبراء الذكاء الاصطناعي والتعلم الآلي من هجمات أطلقوا عليها (هجمات تسمم البيانات) Data-poisoning Aattacks التي يمكن أن تؤثر في مجموعات البيانات الواسعة النطاق المستخدمة بشكل شائع لتدريب نماذج التعلم العميق في العديد من خدمات الذكاء الاصطناعي.





يُشير مصطلح يشير إلى تقديم بيانات خالية من المعنى أو مؤذية بهدف التأثير في أداء نماذج التعلم الآلي وخوارزميات الذكاء الاصطناعي المختلفة التي تعتمد بشكل أساسي على جودة البيانات.
يحدث تسمم البيانات عندما يعبث المهاجمون ببيانات التدريب المستخدمة لإنشاء نماذج التعلم العميق، أو في مرحلة عمل النموذج عن طريق التلاعب بالبيانات المدخلة إليه، وهو ما قد يؤثر في القرارات التي يتخذها الذكاء الاصطناعي بطريقة يصعب تتبعها، ويجعله يقدم تنبؤات غير دقيقة.
ما مدى فعالية هجمات تسمم البيانات؟
من المحتمل أن تكون هجمات تسمم البيانات قوية للغاية لأن الذكاء الاصطناعي سيتعلم من البيانات غير الصحيحة ويمكن أن يتخذ قرارات خاطئة لها عواقب وخيمة، وكل ذلك من خلال طريقة بسيطة للغاية وهي تغيير بيانات المصدر المستخدمة لتدريب خوارزميات التعلم الآلي سرًا.
لا يوجد حاليًا أي دليل على وقوع هجمات في العالم الحقيقي تنطوي على تسمم مجموعات البيانات عبر نطاق الويب، ولكن مجموعة من الباحثين في مجال الذكاء الاصطناعي والتعلم الآلي من جوجل، و(إنفيديا) NVIDIA، و(المعهد الفيدرالي للتكنولوجيا في زيوريخ) ETH Zurich و Robust Intelligence يقولون إنهم أظهروا إمكانية حدوث هجمات تسمم يمكن أن تُطال مجموعات البيانات المتوفرة عبر الويب والمستخدمة لتدريب نماذج التعلم الآلي الأكثر شيوعًا.
وقد حذر الباحثون من أن الكميات الضئيلة من البيانات المضللة في مجموعات التدريب تكفي لإدخال أخطاء مستهدفة في سلوك نموذج الذكاء الاصطناعي.
قال الباحثون إنه باستخدام التقنيات التي ابتكروها لاستغلال الطريقة التي تعمل بها مجموعات البيانات التي جُمعت من الويب، كان بإمكانهم تسميم نسبة 0.01% من مجموعات بيانات التعلم العميق البارزة بجهد ضئيل وبتكلفة منخفضة.
وحذر الباحثون من أن نسبة 0.01% قد تبدو صغيرة الغاية، ولا تمثل إلا جزءًا ضئيلًا جدًا من مجموعات البيانات، ولكنها كافية لتسميم نموذج الذكاء الاصطناعي، ويُعرف هذا الهجوم باسم (تسمم الرؤية المنقسمة) Split-view poisoning، لأنه إذا تمكن المهاجم من السيطرة على مورد ويب مفهرس بواسطة مجموعة بيانات معينة، فيمكنه إفساد البيانات التي جُمعت، مما يجعلها غير دقيقة، مع احتمال التأثير سلبًا في الخوارزمية بأكملها.
قد تُستخدم هجمات تسمم البيانات في إعادة كتابة ميول لغة روبوتات الدردشة التفاعلية، مثل: ChatGPT، و Bard للتحدث بشكل مختلف، أو استخدام لغة مسيئة لإقناع الخوارزميات بأن أداء بعض الشركات سيء، أو أخذ عينات من الفيروسات والبرامج الضارة لإقناعها بأن الملفات الآمنة ضارة، وهذه مجرد أمثلة قليلة لاستخدامات الذكاء الاصطناعي وكيف يمكن للتسمم أن يعطل العمليات.
نظرًا إلى أن نماذج الذكاء الاصطناعي تتعلم مجموعات مهارات متنوعة لأنواع مختلفة من التطبيقات، فإن الطرق التي يمكن للقراصنة استخدامها لتسميم بيانات التدريب واسعة مثل استخداماتها.
كيف يمكن القيام بهجوم تسمم البيانات؟
إحدى الطرق التي يمكن للمهاجمين من خلالها تحقيق هذا الهدف هي ببساطة شراء أسماء نطاقات الإنترنت المنتهية الصلاحية التي تُجمع لتدريب نماذج الذكاء الاصطناعي، ويشير الباحثون إلى أن شراء اسم النطاق واستغلاله لأغراض ضارة ليس فكرة جديدة، إذ يستخدمه مجرمو الإنترنت للمساعدة في نشر البرامج الضارة، ولكن الآن من المحتمل أن يستخدموه في تسميم مجموعة البيانات الواسعة النطاق الموجودة عبر الويب.
بالإضافة إلى ذلك؛ وصف الباحثون نوعًا ثانيًا من الهجوم أطلقوا عليه اسم (تسمم التشغيل الأمامي) front-running poisoning، وفي هذه الحالة لا يتمتع المهاجم بالتحكم الكامل في مجموعة البيانات المحددة، ولكن يمكنه التنبؤ بدقة بموعد وصول المدربين إلى مورد الويب لجمع البيانات لتدريب نموذج الذكاء الاصطناعي، ما يتيح له تضمين البيانات المضللة لتسميم مجموعة البيانات قبل جمعها مباشرة.
وحتى إذا عادت المعلومات إلى النموذج الأصلي الذي لم يتم التلاعب به بعد بضع دقائق فقط، فستظل مجموعة البيانات غير الصحيحة التي سحبتها الخوارزمية عندما كان الهجوم الضار نشيطًا مخزنة في النموذج بشكل دائم.
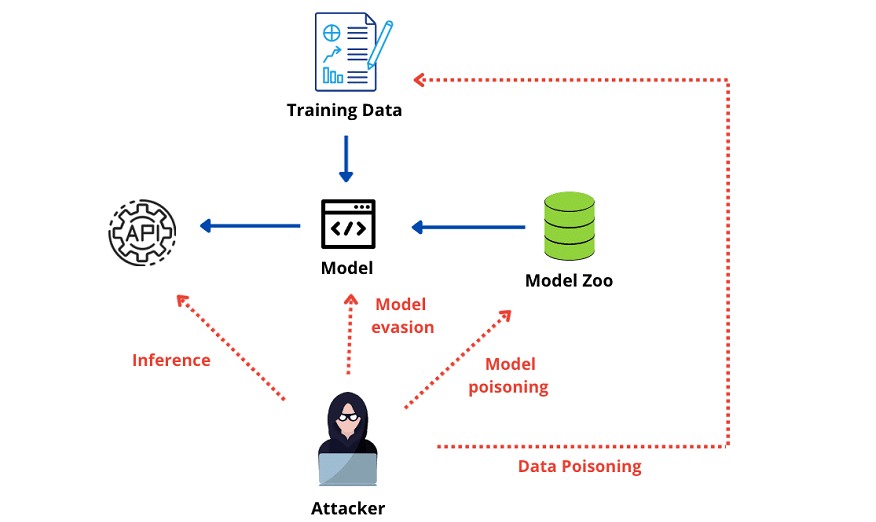
وقد قدم الباحثون مثالًا على أحد الموارد المستخدمة بكثرة للحصول على بيانات التدريب للتعلم الآلي هي موسوعة ويكيبيديا، إذ إن طبيعة عمل ويكيبيديا تعني أنه يمكن لأي شخص تعديل الصفحات في أي وقت، ووفقًا للباحثين يمكن للمهاجم تسميم مجموعة تدريب مصدرها ويكيبيديا عن طريق إجراء تعديلات ضارة، وإجبار النموذج على جمع بيانات غير دقيقة.
تستخدم ويكيبيديا بروتوكولًا موثقًا لجمع البيانات لتدريب نماذج الذكاء الاصطناعي، ما يعني أنه من الممكن التنبؤ بدقة كبيرة بأوقات جمع البيانات من مقالة معينة، ويمكنهم التدخل وتحرير الصفحة بشكل ضار، مما يجبر النموذج على جمع بيانات غير دقيقة، ستُخزن في مجموعة البيانات بشكل دائم.
يعتقد الباحثون أنه من الممكن استغلال هذا البروتوكول لتسميم صفحات ويكيبيديا بنسبة نجاح تصل إلى 6.5%. قد لا تبدو هذه النسبة عالية؛ ولكن العدد الهائل لصفحات ويكيبيديا وطريقة استخدامها لتدريب مجموعات بيانات التعلم الآلي تعني أنه سيكون من الممكن تقديم معلومات غير دقيقة إلى الكثير من النماذج.
نبه الباحثون ويكيبيديا بالهجمات والوسائل المحتملة للدفاع، كما أعلنوا أن الغرض من نشر الورقة البحثية، هو تشجيع الآخرين في المجال الأمني على إجراء أبحاثهم الخاصة حول كيفية الدفاع عن أنظمة الذكاء الاصطناعي والتعلم الآلي من الهجمات الخبيثة.
وقالوا: “إن عملنا ليس سوى نقطة انطلاق للمجتمع لتطوير فهم أفضل للمخاطر التي ينطوي عليها توليد النماذج من البيانات الموجودة عبر الويب”.
هل هناك حل؟
ومن المثير للاهتمام؛ أن التلاعب بنماذج الذكاء الاصطناعي بهذه الطريقة يعكس مشكلة اختبرها متخصصو الأمن السيبراني حول قضايا تدريب الموظفين، إذ غالبًا ما اعتمد المهاجمون على عدم وعي الموظف للتسلل إلى الشركة، من خلال استهداف الموظفين غير المدربين بحيل التصيد الاحتيالي، وهذا هو الحال أيضًا مع تسمم بيانات الذكاء الاصطناعي.
نظرًا إلى أنه لا يزال في مهده، لا يزال متخصصو الأمن السيبراني يتعلمون كيفية الدفاع ضد هجمات تسمم البيانات بأفضل طريقة ممكنة. فقد أشارت بلومبرج إلى أن إحدى الطرق للمساعدة في منع التسمم بالبيانات تتمثل في جعل العلماء الذين يطورون نماذج الذكاء الاصطناعي يتحققون بانتظام من أن جميع الملصقات الموجودة في بيانات التدريب الخاصة بهم دقيقة.
كما نجح خبراء آخرون في استخدام البيانات المفتوحة المصدر بحذر، على الرغم من فوائدها، إذ إنها توفر الوصول إلى المزيد من البيانات لإثراء المصادر الحالية مما يعني أنه من الأسهل تطوير نماذج أكثر دقة، ولكنها تجعل النماذج المدربة هدفًا أسهل للمحتالين والمتسللين.
قد يوفر (اختبار الاختراق) pentesting حلاً أيضًا لأنه لديه القدرة على العثور على نقاط الضعف التي تمنح المتسللين إمكانية الوصول إلى نماذج التدريب على البيانات. يفكر بعض الباحثين أيضًا في تطوير طبقة ثانية من الذكاء الاصطناعي والتعلم الآلي مصممة لتحديد الأخطاء المحتملة في تدريب البيانات.
خاتمة:
ليس هناك شك في أن الذكاء الاصطناعي قد جلب العديد من الفوائد للعالم، ولكنه يثير أيضًا مخاوف أمنية خطيرة، إذ ستصبح الهجمات أكثر صعوبة في الملاحظة بل من الممكن أن يصعب إيقافه، إذ سيتمكن المتسللون من البقاء دون أن يلاحظهم أحد داخل هياكل تكنولوجيا المعلومات المستهدفة لفترة أطول من أي وقت مضى، كما سيؤدي تطوير تقنيات الذكاء الاصطناعي والتعلم الآلي إلى تمكين المتسللين من الوصول إلى قواعد البيانات الكبيرة والتحكم في استخراج البيانات.
في حين أن هذا قد لا يمثل تهديدًا كبيرًا للفرد، إلا أنه يمكن أن يصبح مشكلة أمنية على المستوى العالمي، مع الأخذ في الاعتبار أن التنقيب عن البيانات يُطبق في العديد من المجالات أهمها الأسواق المالية الكبرى، ومجال الرعاية الصحية، وغيرها من المجالات المهمة.


